Maskable PPO¶
Implementation of invalid action masking for the Proximal Policy Optimization(PPO) algorithm. Other than adding support for action masking, the behavior is the same as in SB3’s core PPO algorithm.
Available Policies
Notes¶
Blog post: https://costa.sh/blog-a-closer-look-at-invalid-action-masking-in-policy-gradient-algorithms.html
Additional Blog post: https://boring-guy.sh/posts/masking-rl/
Can I use?¶
Recurrent policies: ❌
Multi processing: ✔️
Gym spaces:
Space |
Action |
Observation |
|---|---|---|
Discrete |
✔️ |
✔️ |
Box |
❌ |
✔️ |
MultiDiscrete |
✔️ |
✔️ |
MultiBinary |
✔️ |
✔️ |
Dict |
❌ |
✔️ |
Example¶
Train a PPO agent on InvalidActionEnvDiscrete. InvalidActionEnvDiscrete has a action_masks method that
returns the invalid action mask (True if the action is valid, False otherwise).
from sb3_contrib import MaskablePPO
from sb3_contrib.common.envs import InvalidActionEnvDiscrete
from sb3_contrib.common.maskable.evaluation import evaluate_policy
from sb3_contrib.common.maskable.utils import get_action_masks
env = InvalidActionEnvDiscrete(dim=80, n_invalid_actions=60)
model = MaskablePPO("MlpPolicy", env, gamma=0.4, seed=32, verbose=1)
model.learn(5000)
evaluate_policy(model, env, n_eval_episodes=20, reward_threshold=90, warn=False)
model.save("ppo_mask")
del model # remove to demonstrate saving and loading
model = MaskablePPO.load("ppo_mask")
obs = env.reset()
while True:
# Retrieve current action mask
action_masks = get_action_masks(env)
action, _states = model.predict(obs, action_masks=action_masks)
obs, rewards, dones, info = env.step(action)
env.render()
If the environment implements the invalid action mask but using a different name, you can use the ActionMasker
to specify the name (see PR #25):
import gym
import numpy as np
from sb3_contrib.common.maskable.policies import MaskableActorCriticPolicy
from sb3_contrib.common.wrappers import ActionMasker
from sb3_contrib.ppo_mask import MaskablePPO
def mask_fn(env: gym.Env) -> np.ndarray:
# Do whatever you'd like in this function to return the action mask
# for the current env. In this example, we assume the env has a
# helpful method we can rely on.
return env.valid_action_mask()
env = ... # Initialize env
env = ActionMasker(env, mask_fn) # Wrap to enable masking
# MaskablePPO behaves the same as SB3's PPO unless the env is wrapped
# with ActionMasker. If the wrapper is detected, the masks are automatically
# retrieved and used when learning. Note that MaskablePPO does not accept
# a new action_mask_fn kwarg, as it did in an earlier draft.
model = MaskablePPO(MaskableActorCriticPolicy, env, verbose=1)
model.learn()
# Note that use of masks is manual and optional outside of learning,
# so masking can be "removed" at testing time
model.predict(observation, action_masks=valid_action_array)
Results¶
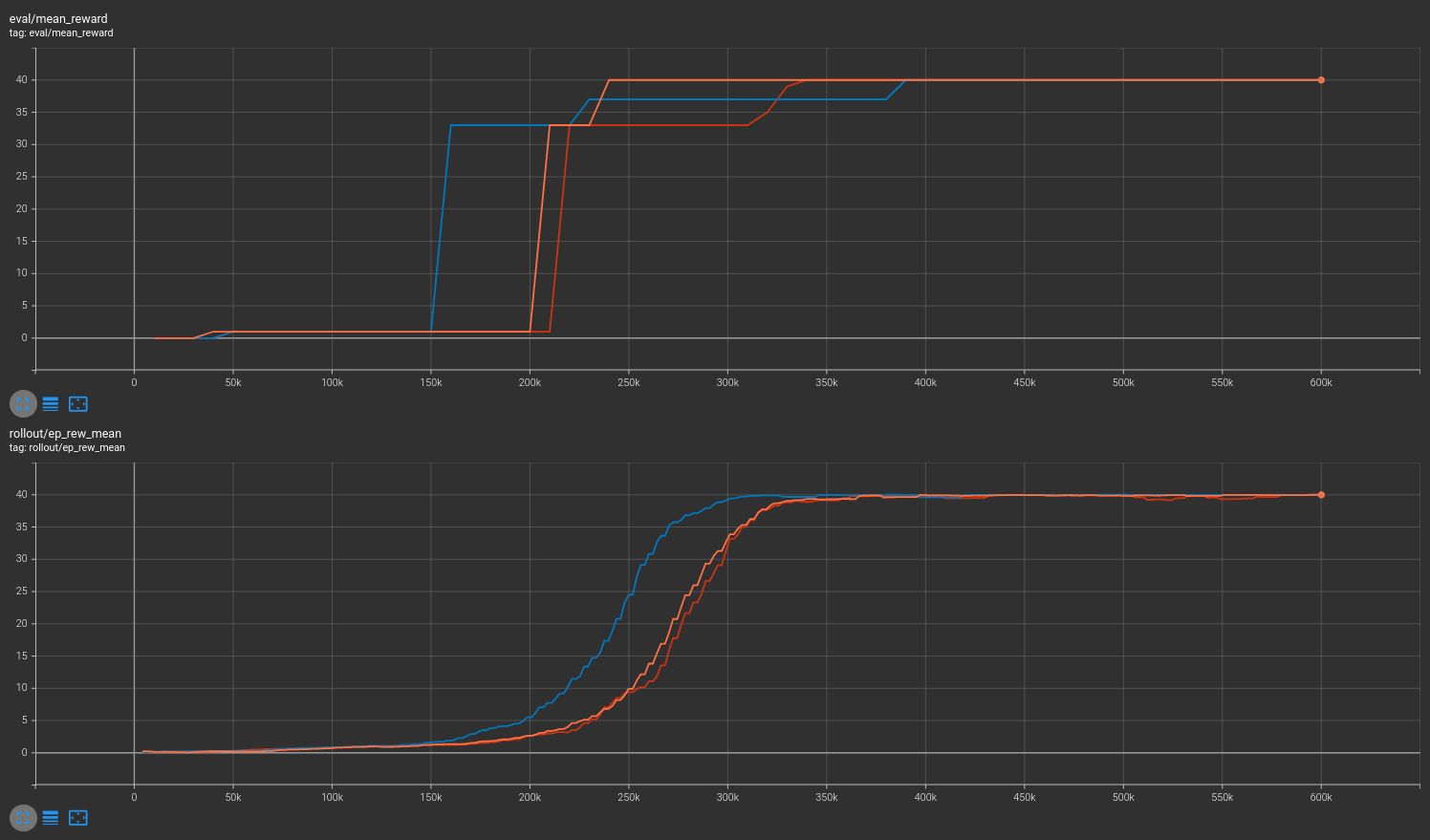
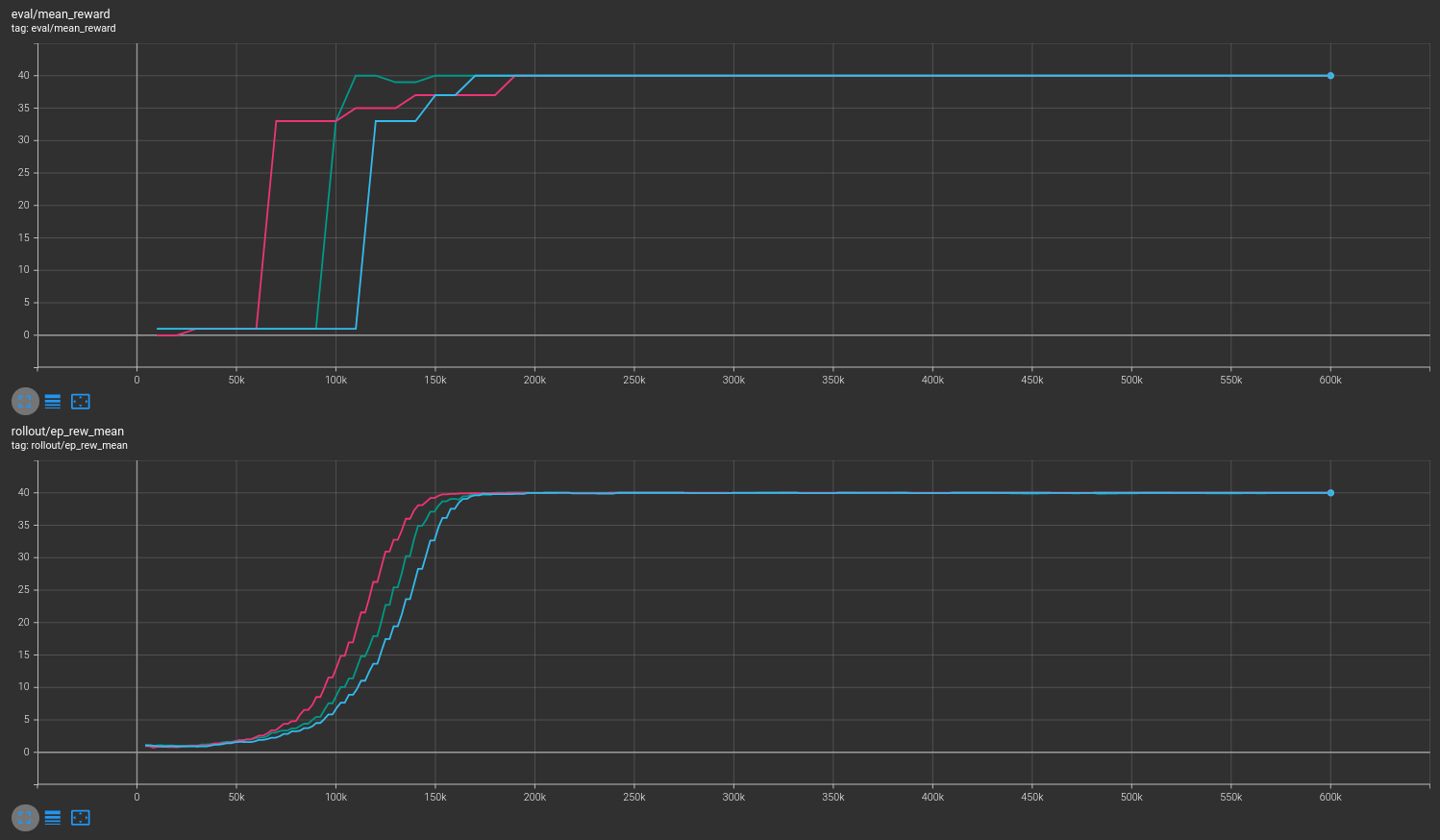
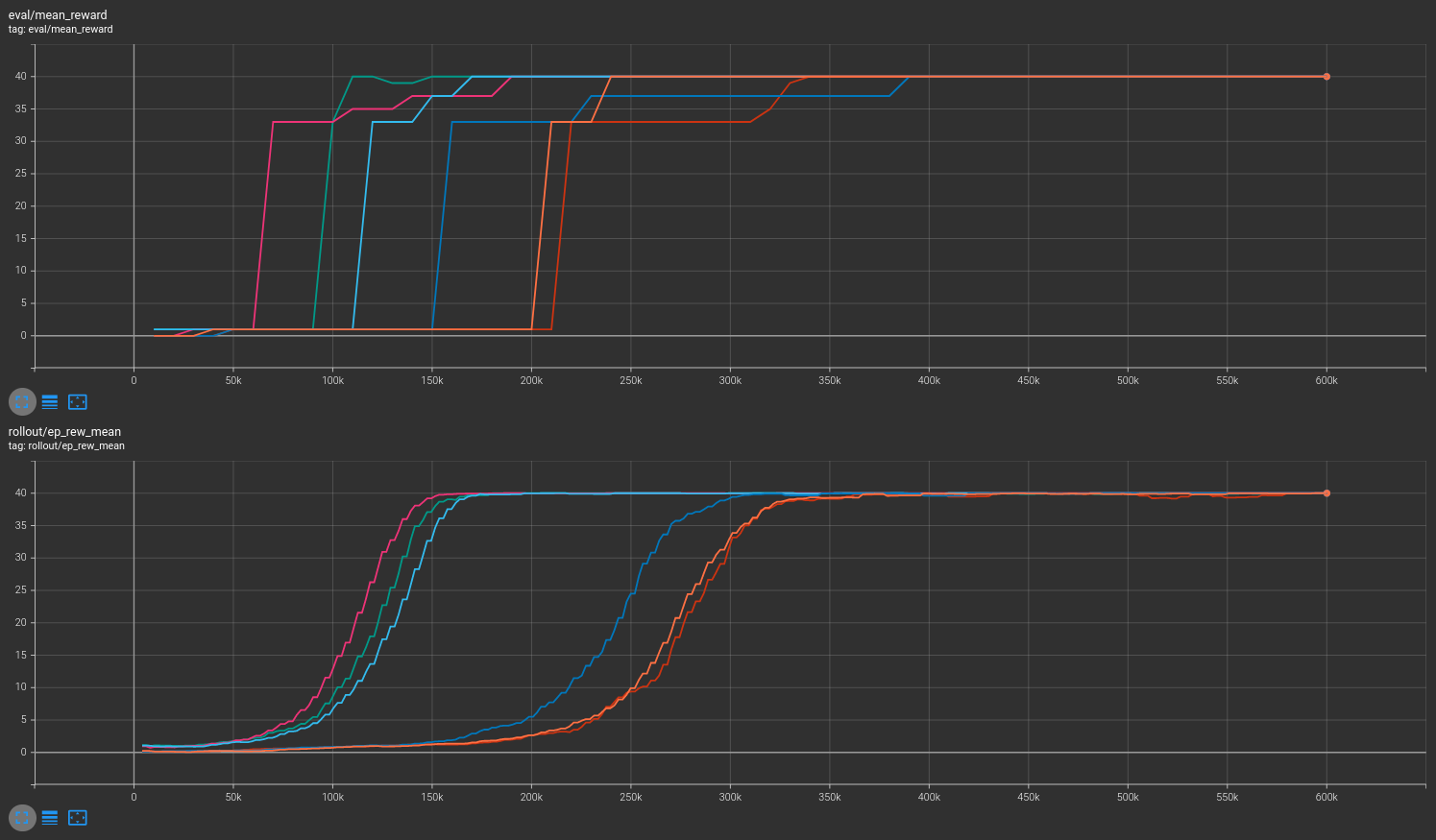
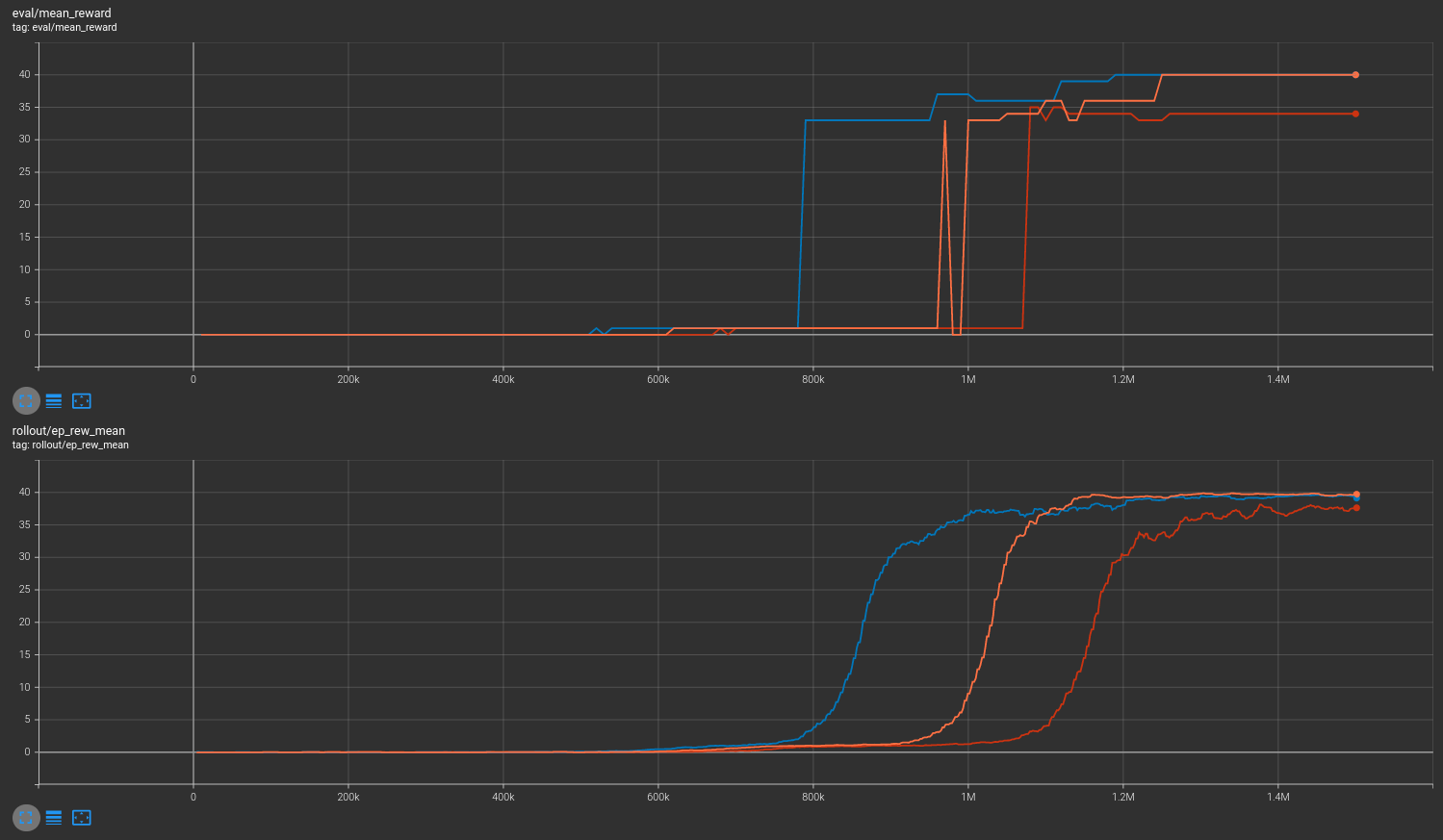
Results are shown for two MicroRTS benchmarks: MicrortsMining4x4F9-v0 (600K steps) and MicrortsMining10x10F9-v0 (1.5M steps). For each, models were trained with and without masking, using 3 seeds.
4x4¶
No masking¶
With masking¶
Combined¶
10x10¶
No masking¶
With masking¶
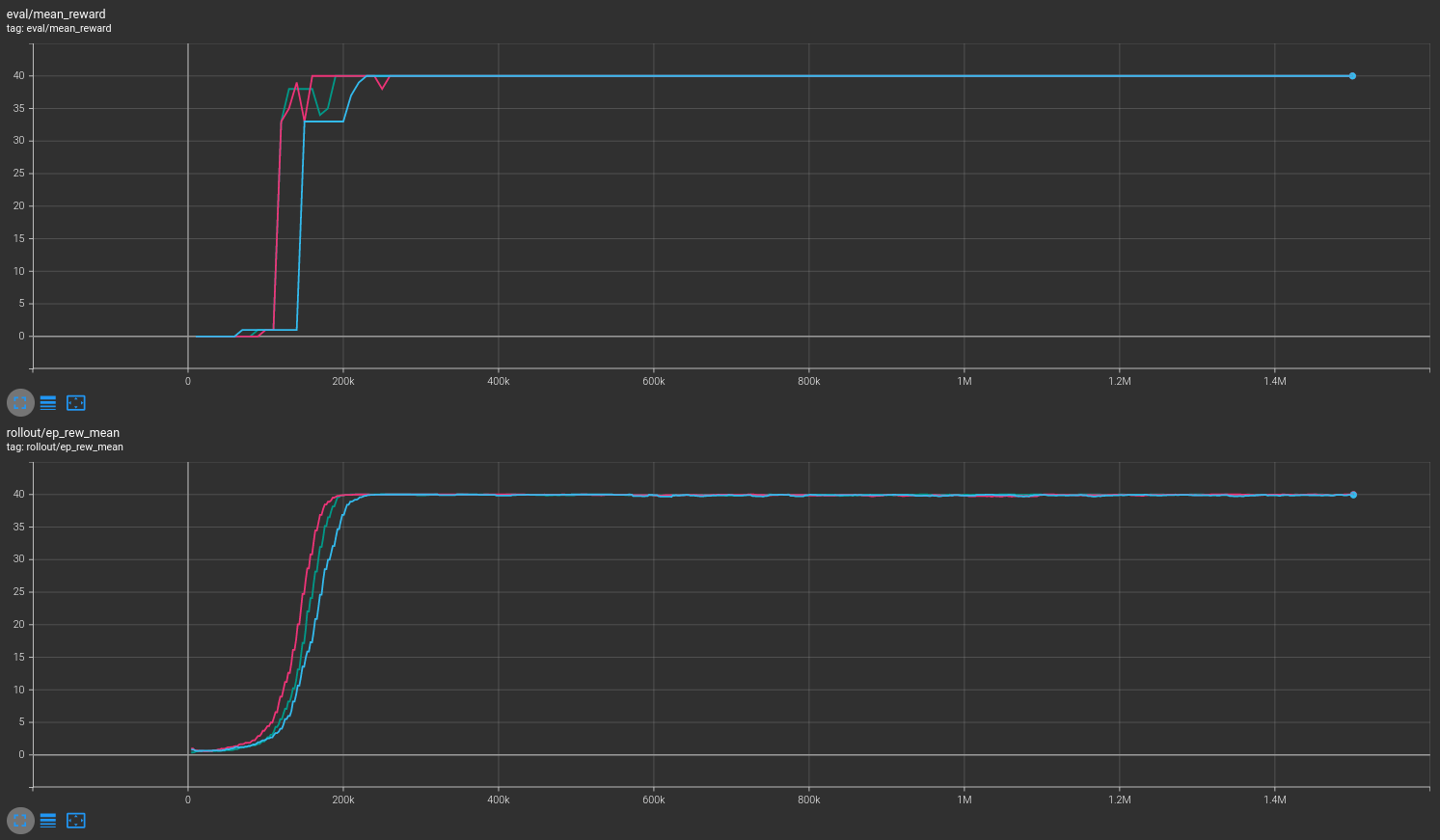
Combined¶
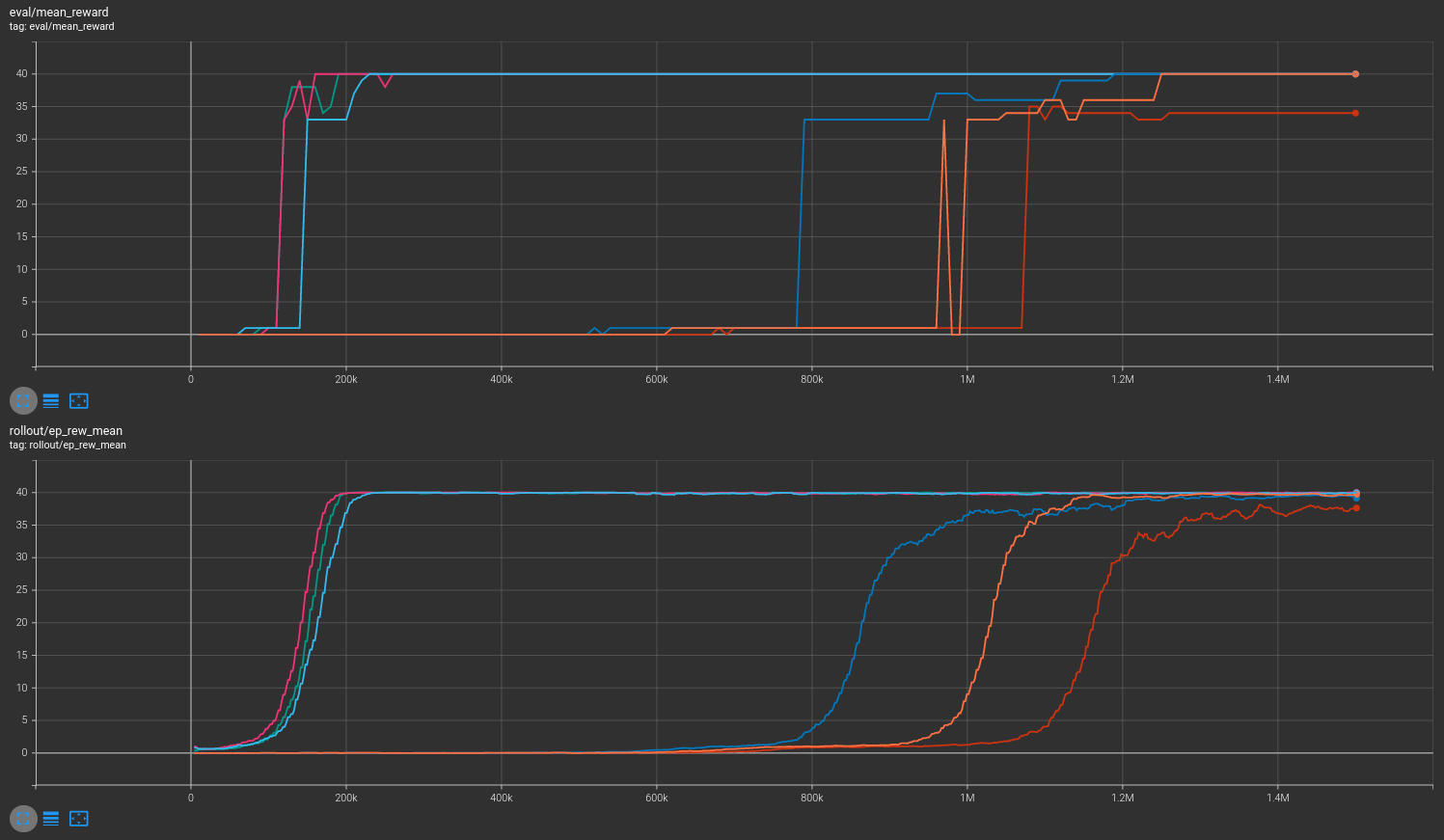
More information may be found in the associated PR.
How to replicate the results?¶
Clone the repo for the experiment:
git clone git@github.com:kronion/microrts-ppo-comparison.git
cd microrts-ppo-comparison
Install dependencies:
# Install MicroRTS:
rm -fR ~/microrts && mkdir ~/microrts && \
wget -O ~/microrts/microrts.zip http://microrts.s3.amazonaws.com/microrts/artifacts/202004222224.microrts.zip && \
unzip ~/microrts/microrts.zip -d ~/microrts/
# You may want to make a venv before installing packages
pip install -r requirements.txt
Train several times with various seeds, with and without masking:
# python sb/train_ppo.py [output dir] [MicroRTS map size] [--mask] [--seed int]
# 4x4 unmasked
python sb3/train_ppo.py zoo 4 --seed 42
python sb3/train_ppo.py zoo 4 --seed 43
python sb3/train_ppo.py zoo 4 --seed 44
# 4x4 masked
python sb3/train_ppo.py zoo 4 --mask --seed 42
python sb3/train_ppo.py zoo 4 --mask --seed 43
python sb3/train_ppo.py zoo 4 --mask --seed 44
# 10x10 unmasked
python sb3/train_ppo.py zoo 10 --seed 42
python sb3/train_ppo.py zoo 10 --seed 43
python sb3/train_ppo.py zoo 10 --seed 44
# 10x10 masked
python sb3/train_ppo.py zoo 10 --mask --seed 42
python sb3/train_ppo.py zoo 10 --mask --seed 43
python sb3/train_ppo.py zoo 10 --mask --seed 44
View the tensorboard log output:
# For 4x4 environment
tensorboard --logdir zoo/4x4/runs
# For 10x10 environment
tensorboard --logdir zoo/10x10/runs