Maskable PPO¶
Implementation of invalid action masking for the Proximal Policy Optimization (PPO) algorithm. Other than adding support for action masking, the behavior is the same as in SB3’s core PPO algorithm.
Available Policies
alias of |
|
alias of |
|
alias of |
Notes¶
Blog post: https://costa.sh/blog-a-closer-look-at-invalid-action-masking-in-policy-gradient-algorithms.html
Additional Blog post: https://boring-guy.sh/posts/masking-rl/
Can I use?¶
Recurrent policies: ❌
Multi processing: ✔️
Gym spaces:
Space |
Action |
Observation |
|---|---|---|
Discrete |
✔️ |
✔️ |
Box |
❌ |
✔️ |
MultiDiscrete |
✔️ |
✔️ |
MultiBinary |
✔️ |
✔️ |
Dict |
❌ |
✔️ |
Example¶
Train a PPO agent on InvalidActionEnvDiscrete. InvalidActionEnvDiscrete has a action_masks method that
returns the invalid action mask (True if the action is valid, False otherwise).
from sb3_contrib import MaskablePPO
from sb3_contrib.common.envs import InvalidActionEnvDiscrete
from sb3_contrib.common.maskable.evaluation import evaluate_policy
from sb3_contrib.common.maskable.utils import get_action_masks
env = InvalidActionEnvDiscrete(dim=80, n_invalid_actions=60)
model = MaskablePPO("MlpPolicy", env, gamma=0.4, seed=32, verbose=1)
model.learn(5000)
evaluate_policy(model, env, n_eval_episodes=20, reward_threshold=90, warn=False)
model.save("ppo_mask")
del model # remove to demonstrate saving and loading
model = MaskablePPO.load("ppo_mask")
obs = env.reset()
while True:
# Retrieve current action mask
action_masks = get_action_masks(env)
action, _states = model.predict(obs, action_masks=action_masks)
obs, rewards, dones, info = env.step(action)
env.render()
If the environment implements the invalid action mask but using a different name, you can use the ActionMasker
to specify the name (see PR #25):
import gym
import numpy as np
from sb3_contrib.common.maskable.policies import MaskableActorCriticPolicy
from sb3_contrib.common.wrappers import ActionMasker
from sb3_contrib.ppo_mask import MaskablePPO
def mask_fn(env: gym.Env) -> np.ndarray:
# Do whatever you'd like in this function to return the action mask
# for the current env. In this example, we assume the env has a
# helpful method we can rely on.
return env.valid_action_mask()
env = ... # Initialize env
env = ActionMasker(env, mask_fn) # Wrap to enable masking
# MaskablePPO behaves the same as SB3's PPO unless the env is wrapped
# with ActionMasker. If the wrapper is detected, the masks are automatically
# retrieved and used when learning. Note that MaskablePPO does not accept
# a new action_mask_fn kwarg, as it did in an earlier draft.
model = MaskablePPO(MaskableActorCriticPolicy, env, verbose=1)
model.learn()
# Note that use of masks is manual and optional outside of learning,
# so masking can be "removed" at testing time
model.predict(observation, action_masks=valid_action_array)
Results¶
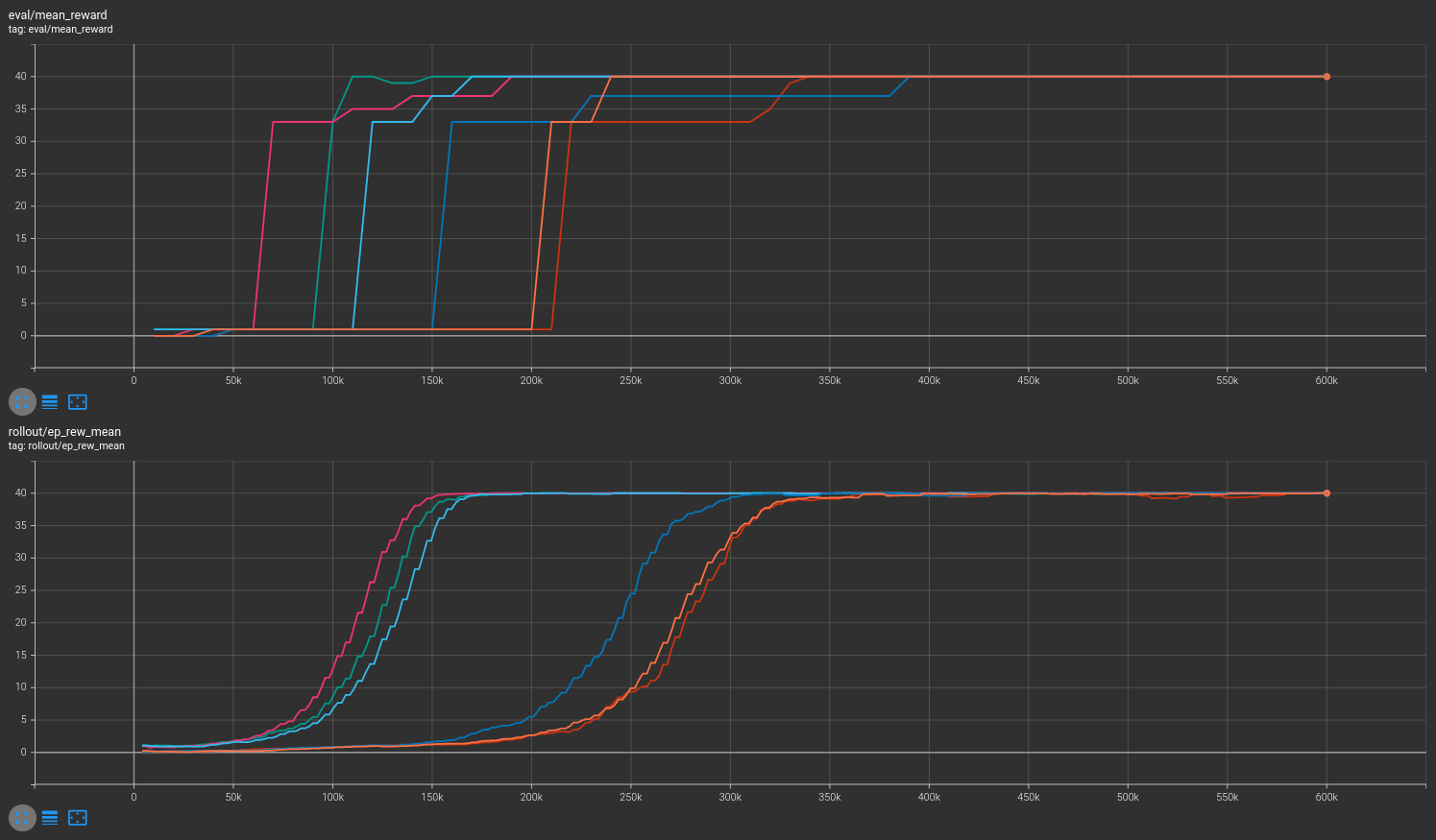
Results are shown for two MicroRTS benchmarks: MicrortsMining4x4F9-v0 (600K steps) and MicrortsMining10x10F9-v0 (1.5M steps). For each, models were trained with and without masking, using 3 seeds.
4x4¶
No masking¶
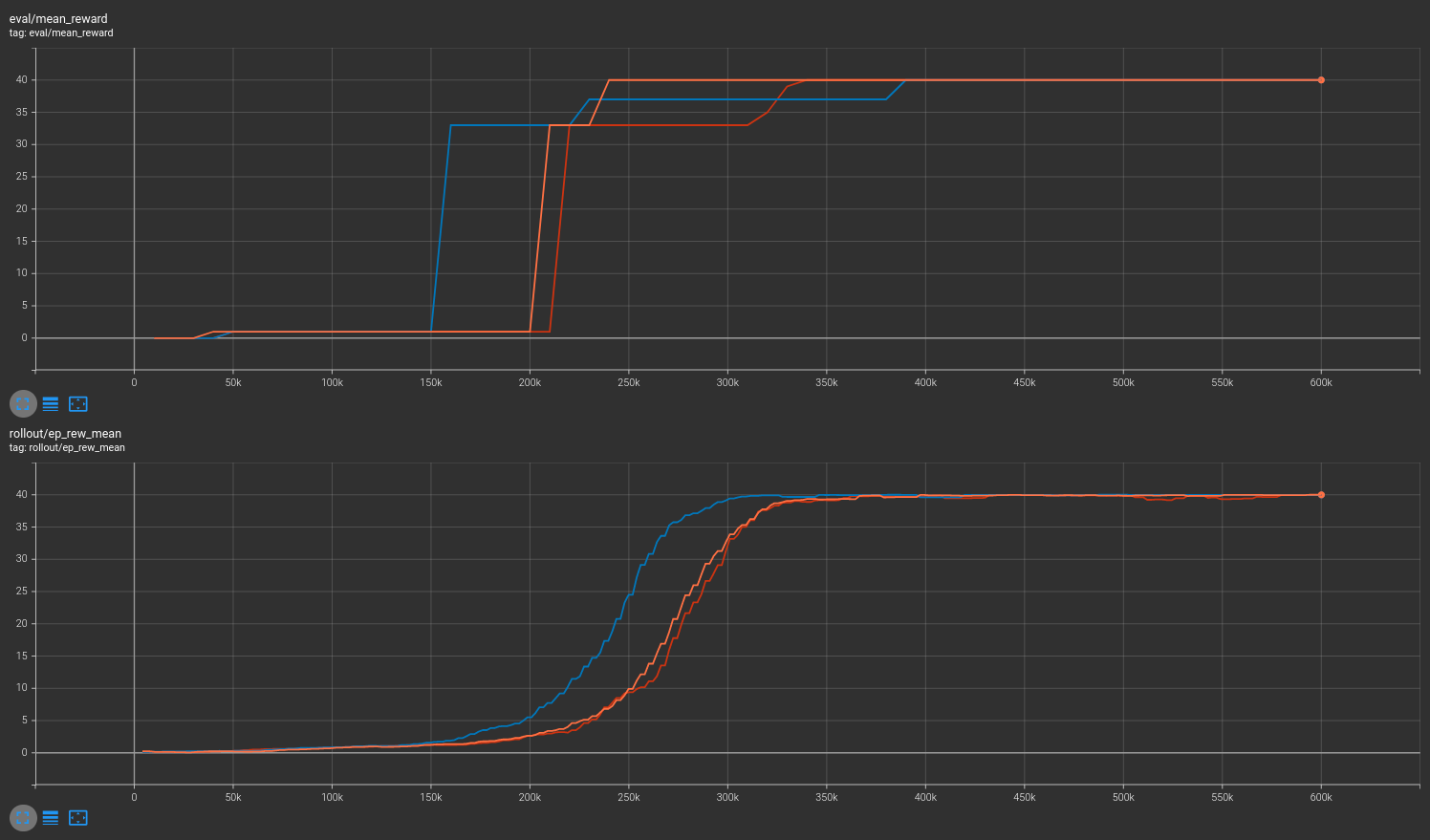
With masking¶
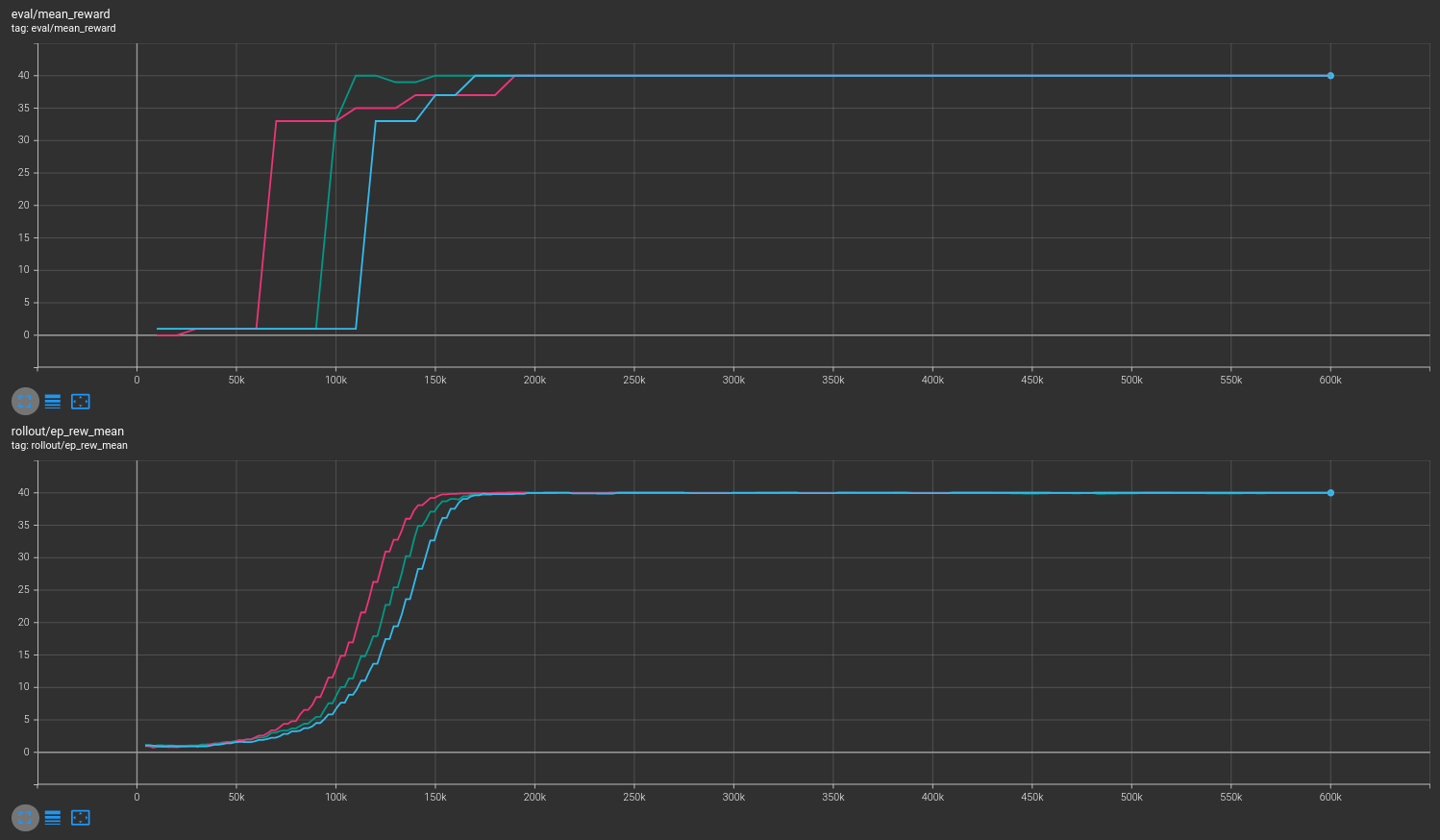
Combined¶
10x10¶
No masking¶
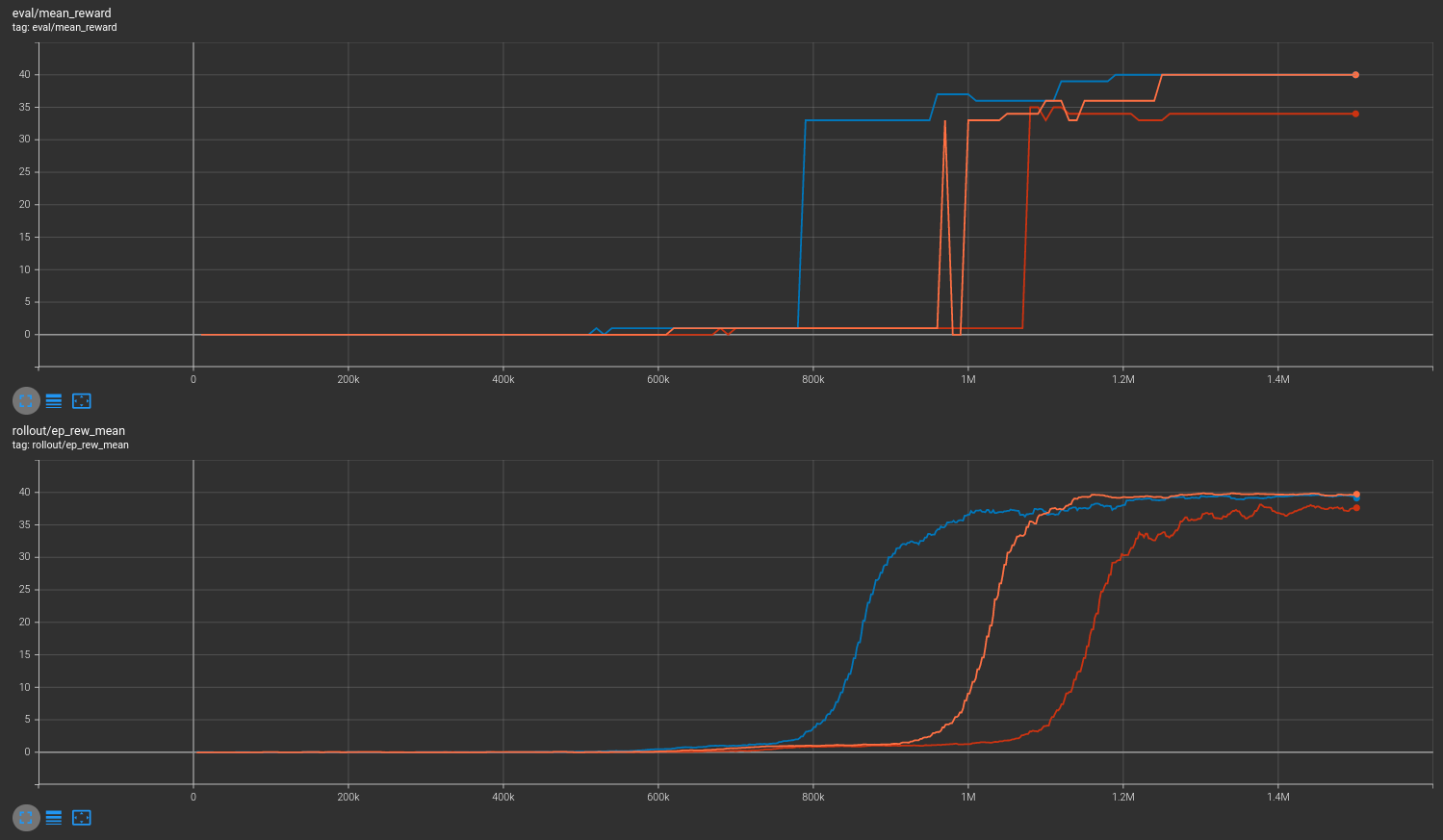
With masking¶
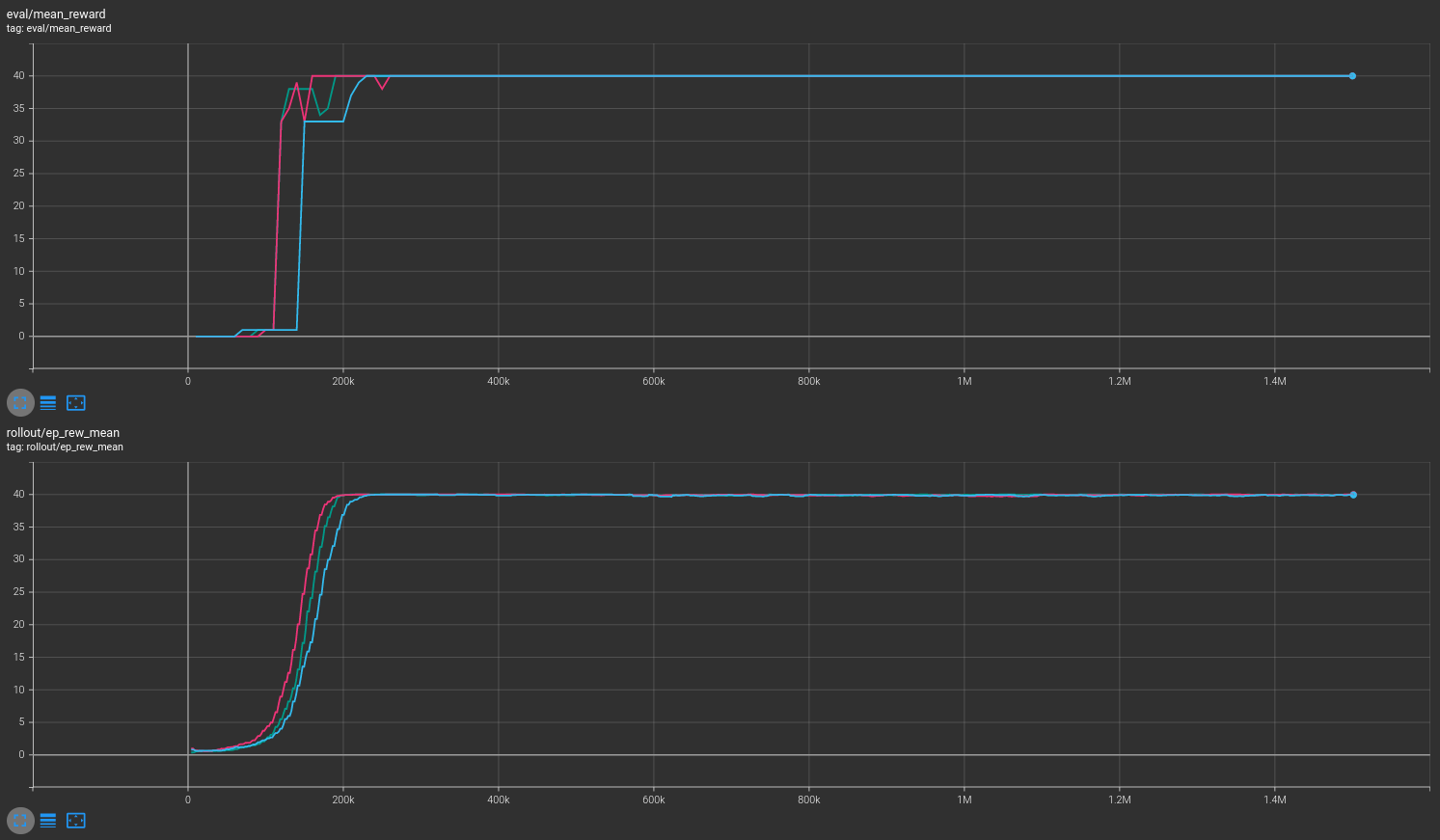
Combined¶
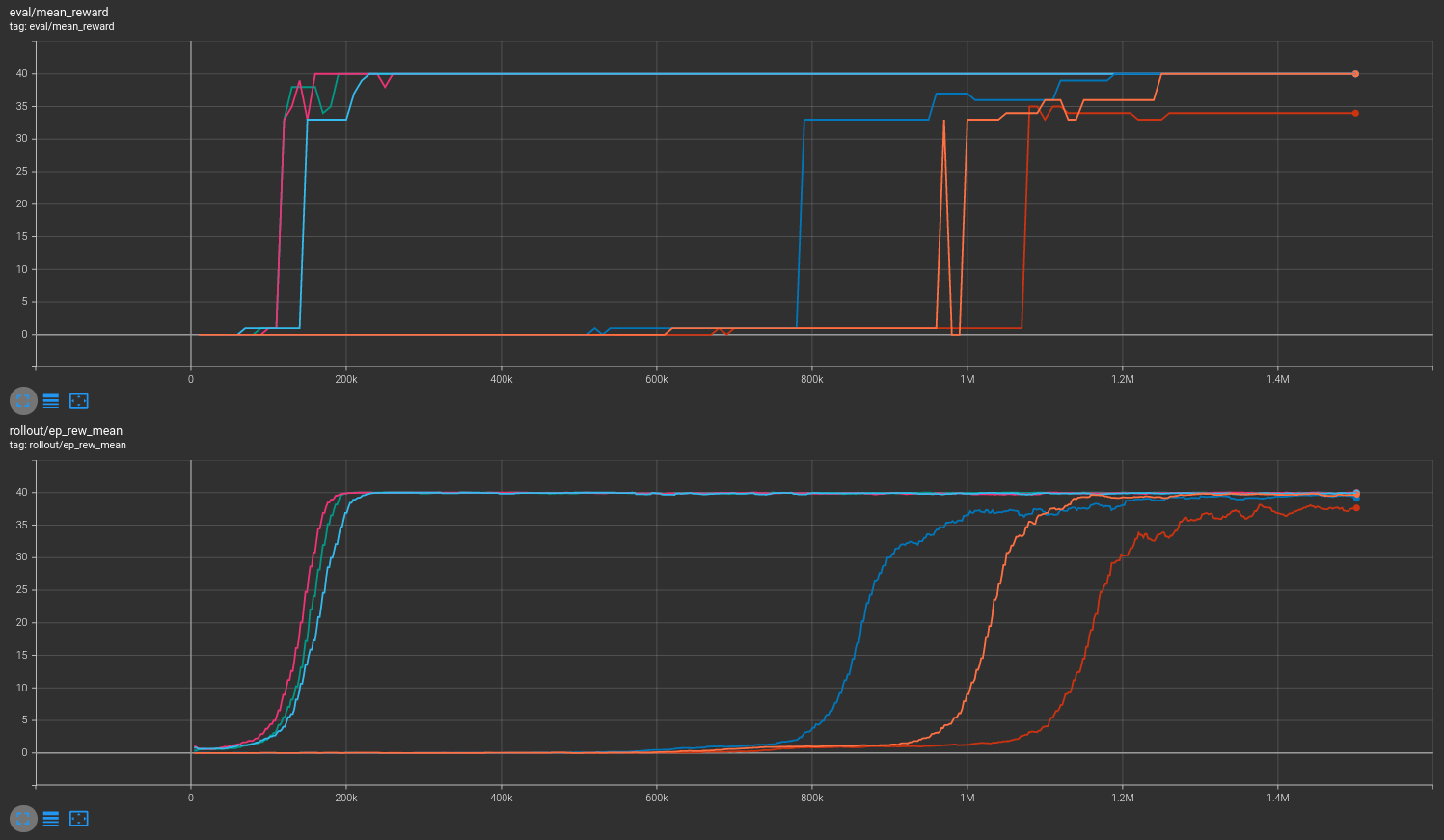
More information may be found in the associated PR.
How to replicate the results?¶
Clone the repo for the experiment:
git clone git@github.com:kronion/microrts-ppo-comparison.git
cd microrts-ppo-comparison
Install dependencies:
# Install MicroRTS:
rm -fR ~/microrts && mkdir ~/microrts && \
wget -O ~/microrts/microrts.zip http://microrts.s3.amazonaws.com/microrts/artifacts/202004222224.microrts.zip && \
unzip ~/microrts/microrts.zip -d ~/microrts/
# You may want to make a venv before installing packages
pip install -r requirements.txt
Train several times with various seeds, with and without masking:
# python sb/train_ppo.py [output dir] [MicroRTS map size] [--mask] [--seed int]
# 4x4 unmasked
python sb3/train_ppo.py zoo 4 --seed 42
python sb3/train_ppo.py zoo 4 --seed 43
python sb3/train_ppo.py zoo 4 --seed 44
# 4x4 masked
python sb3/train_ppo.py zoo 4 --mask --seed 42
python sb3/train_ppo.py zoo 4 --mask --seed 43
python sb3/train_ppo.py zoo 4 --mask --seed 44
# 10x10 unmasked
python sb3/train_ppo.py zoo 10 --seed 42
python sb3/train_ppo.py zoo 10 --seed 43
python sb3/train_ppo.py zoo 10 --seed 44
# 10x10 masked
python sb3/train_ppo.py zoo 10 --mask --seed 42
python sb3/train_ppo.py zoo 10 --mask --seed 43
python sb3/train_ppo.py zoo 10 --mask --seed 44
View the tensorboard log output:
# For 4x4 environment
tensorboard --logdir zoo/4x4/runs
# For 10x10 environment
tensorboard --logdir zoo/10x10/runs
Parameters¶
- class sb3_contrib.ppo_mask.MaskablePPO(policy, env, learning_rate=0.0003, n_steps=2048, batch_size=64, n_epochs=10, gamma=0.99, gae_lambda=0.95, clip_range=0.2, clip_range_vf=None, normalize_advantage=True, ent_coef=0.0, vf_coef=0.5, max_grad_norm=0.5, target_kl=None, tensorboard_log=None, create_eval_env=False, policy_kwargs=None, verbose=0, seed=None, device='auto', _init_setup_model=True)[source]¶
Proximal Policy Optimization algorithm (PPO) (clip version) with Invalid Action Masking.
Based on the original Stable Baselines 3 implementation.
Introduction to PPO: https://spinningup.openai.com/en/latest/algorithms/ppo.html Background on Invalid Action Masking: https://arxiv.org/abs/2006.14171
- Parameters:
policy (
Union[str,Type[MaskableActorCriticPolicy]]) – The policy model to use (MlpPolicy, CnnPolicy, …)env (
Union[Env,VecEnv,str]) – The environment to learn from (if registered in Gym, can be str)learning_rate (
Union[float,Callable[[float],float]]) – The learning rate, it can be a function of the current progress remaining (from 1 to 0)n_steps (
int) – The number of steps to run for each environment per update (i.e. batch size is n_steps * n_env where n_env is number of environment copies running in parallel)batch_size (
Optional[int]) – Minibatch sizen_epochs (
int) – Number of epoch when optimizing the surrogate lossgamma (
float) – Discount factorgae_lambda (
float) – Factor for trade-off of bias vs variance for Generalized Advantage Estimatorclip_range (
Union[float,Callable[[float],float]]) – Clipping parameter, it can be a function of the current progress remaining (from 1 to 0).clip_range_vf (
Union[None,float,Callable[[float],float]]) – Clipping parameter for the value function, it can be a function of the current progress remaining (from 1 to 0). This is a parameter specific to the OpenAI implementation. If None is passed (default), no clipping will be done on the value function. IMPORTANT: this clipping depends on the reward scaling.normalize_advantage (
bool) – Whether to normalize or not the advantageent_coef (
float) – Entropy coefficient for the loss calculationvf_coef (
float) – Value function coefficient for the loss calculationmax_grad_norm (
float) – The maximum value for the gradient clippingtarget_kl (
Optional[float]) – Limit the KL divergence between updates, because the clipping is not enough to prevent large update see issue #213 (cf https://github.com/hill-a/stable-baselines/issues/213) By default, there is no limit on the kl div.tensorboard_log (
Optional[str]) – the log location for tensorboard (if None, no logging)create_eval_env (
bool) – Whether to create a second environment that will be used for evaluating the agent periodically (Only available when passing string for the environment). Caution, this parameter is deprecated and will be removed in the future.policy_kwargs (
Optional[Dict[str,Any]]) – additional arguments to be passed to the policy on creationverbose (
int) – the verbosity level: 0 no output, 1 info, 2 debugseed (
Optional[int]) – Seed for the pseudo random generatorsdevice (
Union[device,str]) – Device (cpu, cuda, …) on which the code should be run. Setting it to auto, the code will be run on the GPU if possible._init_setup_model (
bool) – Whether or not to build the network at the creation of the instance
- collect_rollouts(env, callback, rollout_buffer, n_rollout_steps, use_masking=True)[source]¶
Collect experiences using the current policy and fill a
RolloutBuffer. The term rollout here refers to the model-free notion and should not be used with the concept of rollout used in model-based RL or planning.This method is largely identical to the implementation found in the parent class.
- Parameters:
env (
VecEnv) – The training environmentcallback (
BaseCallback) – Callback that will be called at each step (and at the beginning and end of the rollout)rollout_buffer (
RolloutBuffer) – Buffer to fill with rolloutsn_steps – Number of experiences to collect per environment
use_masking (
bool) – Whether or not to use invalid action masks during training
- Return type:
bool- Returns:
True if function returned with at least n_rollout_steps collected, False if callback terminated rollout prematurely.
- get_env()¶
Returns the current environment (can be None if not defined).
- Return type:
Optional[VecEnv]- Returns:
The current environment
- get_parameters()¶
Return the parameters of the agent. This includes parameters from different networks, e.g. critics (value functions) and policies (pi functions).
- Return type:
Dict[str,Dict]- Returns:
Mapping of from names of the objects to PyTorch state-dicts.
- get_vec_normalize_env()¶
Return the
VecNormalizewrapper of the training env if it exists.- Return type:
Optional[VecNormalize]- Returns:
The
VecNormalizeenv.
- learn(total_timesteps, callback=None, log_interval=1, eval_env=None, eval_freq=-1, n_eval_episodes=5, tb_log_name='PPO', eval_log_path=None, reset_num_timesteps=True, use_masking=True, progress_bar=False)[source]¶
Return a trained model.
- Parameters:
total_timesteps (
int) – The total number of samples (env steps) to train oncallback (
Union[None,Callable,List[BaseCallback],BaseCallback]) – callback(s) called at every step with state of the algorithm.log_interval (
int) – The number of timesteps before logging.tb_log_name (
str) – the name of the run for TensorBoard loggingreset_num_timesteps (
bool) – whether or not to reset the current timestep number (used in logging)progress_bar (
bool) – Display a progress bar using tqdm and rich.
- Return type:
TypeVar(MaskablePPOSelf, bound= MaskablePPO)- Returns:
the trained model
- classmethod load(path, env=None, device='auto', custom_objects=None, print_system_info=False, force_reset=True, **kwargs)¶
Load the model from a zip-file. Warning:
loadre-creates the model from scratch, it does not update it in-place! For an in-place load useset_parametersinstead.- Parameters:
path (
Union[str,Path,BufferedIOBase]) – path to the file (or a file-like) where to load the agent fromenv (
Union[Env,VecEnv,None]) – the new environment to run the loaded model on (can be None if you only need prediction from a trained model) has priority over any saved environmentdevice (
Union[device,str]) – Device on which the code should run.custom_objects (
Optional[Dict[str,Any]]) – Dictionary of objects to replace upon loading. If a variable is present in this dictionary as a key, it will not be deserialized and the corresponding item will be used instead. Similar to custom_objects inkeras.models.load_model. Useful when you have an object in file that can not be deserialized.print_system_info (
bool) – Whether to print system info from the saved model and the current system info (useful to debug loading issues)force_reset (
bool) – Force call toreset()before training to avoid unexpected behavior. See https://github.com/DLR-RM/stable-baselines3/issues/597kwargs – extra arguments to change the model when loading
- Return type:
TypeVar(SelfBaseAlgorithm, bound= BaseAlgorithm)- Returns:
new model instance with loaded parameters
- property logger: Logger¶
Getter for the logger object.
- predict(observation, state=None, episode_start=None, deterministic=False, action_masks=None)[source]¶
Get the policy action from an observation (and optional hidden state). Includes sugar-coating to handle different observations (e.g. normalizing images).
- Parameters:
observation (
ndarray) – the input observationstate (
Optional[Tuple[ndarray,...]]) – The last hidden states (can be None, used in recurrent policies)episode_start (
Optional[ndarray]) – The last masks (can be None, used in recurrent policies) this correspond to beginning of episodes, where the hidden states of the RNN must be reset.deterministic (
bool) – Whether or not to return deterministic actions.
- Return type:
Tuple[ndarray,Optional[Tuple[ndarray,...]]]- Returns:
the model’s action and the next hidden state (used in recurrent policies)
- save(path, exclude=None, include=None)¶
Save all the attributes of the object and the model parameters in a zip-file.
- Parameters:
path (
Union[str,Path,BufferedIOBase]) – path to the file where the rl agent should be savedexclude (
Optional[Iterable[str]]) – name of parameters that should be excluded in addition to the default onesinclude (
Optional[Iterable[str]]) – name of parameters that might be excluded but should be included anyway
- Return type:
None
- set_env(env, force_reset=True)¶
Checks the validity of the environment, and if it is coherent, set it as the current environment. Furthermore wrap any non vectorized env into a vectorized checked parameters: - observation_space - action_space
- Parameters:
env (
Union[Env,VecEnv]) – The environment for learning a policyforce_reset (
bool) – Force call toreset()before training to avoid unexpected behavior. See issue https://github.com/DLR-RM/stable-baselines3/issues/597
- Return type:
None
- set_logger(logger)¶
Setter for for logger object. :rtype:
NoneWarning
When passing a custom logger object, this will overwrite
tensorboard_logandverbosesettings passed to the constructor.
- set_parameters(load_path_or_dict, exact_match=True, device='auto')¶
Load parameters from a given zip-file or a nested dictionary containing parameters for different modules (see
get_parameters).- Parameters:
load_path_or_iter – Location of the saved data (path or file-like, see
save), or a nested dictionary containing nn.Module parameters used by the policy. The dictionary maps object names to a state-dictionary returned bytorch.nn.Module.state_dict().exact_match (
bool) – If True, the given parameters should include parameters for each module and each of their parameters, otherwise raises an Exception. If set to False, this can be used to update only specific parameters.device (
Union[device,str]) – Device on which the code should run.
- Return type:
None
- set_random_seed(seed=None)¶
Set the seed of the pseudo-random generators (python, numpy, pytorch, gym, action_space)
- Parameters:
seed (
Optional[int]) –- Return type:
None
MaskablePPO Policies¶
- sb3_contrib.ppo_mask.MlpPolicy¶
alias of
MaskableActorCriticPolicy
- class sb3_contrib.common.maskable.policies.MaskableActorCriticPolicy(observation_space, action_space, lr_schedule, net_arch=None, activation_fn=<class 'torch.nn.modules.activation.Tanh'>, ortho_init=True, features_extractor_class=<class 'stable_baselines3.common.torch_layers.FlattenExtractor'>, features_extractor_kwargs=None, normalize_images=True, optimizer_class=<class 'torch.optim.adam.Adam'>, optimizer_kwargs=None)[source]
Policy class for actor-critic algorithms (has both policy and value prediction). Used by A2C, PPO and the likes.
- Parameters:
observation_space (
Space) – Observation spaceaction_space (
Space) – Action spacelr_schedule (
Callable[[float],float]) – Learning rate schedule (could be constant)net_arch (
Optional[List[Union[int,Dict[str,List[int]]]]]) – The specification of the policy and value networks.activation_fn (
Type[Module]) – Activation functionortho_init (
bool) – Whether to use or not orthogonal initializationfeatures_extractor_class (
Type[BaseFeaturesExtractor]) – Features extractor to use.features_extractor_kwargs (
Optional[Dict[str,Any]]) – Keyword arguments to pass to the features extractor.normalize_images (
bool) – Whether to normalize images or not, dividing by 255.0 (True by default)optimizer_class (
Type[Optimizer]) – The optimizer to use,th.optim.Adamby defaultoptimizer_kwargs (
Optional[Dict[str,Any]]) – Additional keyword arguments, excluding the learning rate, to pass to the optimizer
- evaluate_actions(obs, actions, action_masks=None)[source]
Evaluate actions according to the current policy, given the observations.
- Parameters:
obs (
Tensor) –actions (
Tensor) –
- Return type:
Tuple[Tensor,Tensor,Tensor]- Returns:
estimated value, log likelihood of taking those actions and entropy of the action distribution.
- forward(obs, deterministic=False, action_masks=None)[source]
Forward pass in all the networks (actor and critic)
- Parameters:
obs (
Tensor) – Observationdeterministic (
bool) – Whether to sample or use deterministic actionsaction_masks (
Optional[ndarray]) – Action masks to apply to the action distribution
- Return type:
Tuple[Tensor,Tensor,Tensor]- Returns:
action, value and log probability of the action
- get_distribution(obs, action_masks=None)[source]
Get the current policy distribution given the observations.
- Parameters:
obs (
Tensor) –action_masks (
Optional[ndarray]) –
- Return type:
MaskableDistribution- Returns:
the action distribution.
- predict(observation, state=None, episode_start=None, deterministic=False, action_masks=None)[source]
Get the policy action from an observation (and optional hidden state). Includes sugar-coating to handle different observations (e.g. normalizing images).
- Parameters:
observation (
Union[ndarray,Dict[str,ndarray]]) – the input observationstate (
Optional[Tuple[ndarray,...]]) – The last states (can be None, used in recurrent policies)episode_start (
Optional[ndarray]) – The last masks (can be None, used in recurrent policies)deterministic (
bool) – Whether or not to return deterministic actions.action_masks (
Optional[ndarray]) – Action masks to apply to the action distribution
- Return type:
Tuple[ndarray,Optional[Tuple[ndarray,...]]]- Returns:
the model’s action and the next state (used in recurrent policies)
- predict_values(obs)[source]
Get the estimated values according to the current policy given the observations.
- Parameters:
obs (
Tensor) –- Return type:
Tensor- Returns:
the estimated values.
- sb3_contrib.ppo_mask.CnnPolicy¶
alias of
MaskableActorCriticCnnPolicy
- class sb3_contrib.common.maskable.policies.MaskableActorCriticCnnPolicy(observation_space, action_space, lr_schedule, net_arch=None, activation_fn=<class 'torch.nn.modules.activation.Tanh'>, ortho_init=True, features_extractor_class=<class 'stable_baselines3.common.torch_layers.NatureCNN'>, features_extractor_kwargs=None, normalize_images=True, optimizer_class=<class 'torch.optim.adam.Adam'>, optimizer_kwargs=None)[source]
CNN policy class for actor-critic algorithms (has both policy and value prediction). Used by A2C, PPO and the likes.
- Parameters:
observation_space (
Space) – Observation spaceaction_space (
Space) – Action spacelr_schedule (
Callable[[float],float]) – Learning rate schedule (could be constant)net_arch (
Optional[List[Union[int,Dict[str,List[int]]]]]) – The specification of the policy and value networks.activation_fn (
Type[Module]) – Activation functionortho_init (
bool) – Whether to use or not orthogonal initializationfeatures_extractor_class (
Type[BaseFeaturesExtractor]) – Features extractor to use.features_extractor_kwargs (
Optional[Dict[str,Any]]) – Keyword arguments to pass to the features extractor.normalize_images (
bool) – Whether to normalize images or not, dividing by 255.0 (True by default)optimizer_class (
Type[Optimizer]) – The optimizer to use,th.optim.Adamby defaultoptimizer_kwargs (
Optional[Dict[str,Any]]) – Additional keyword arguments, excluding the learning rate, to pass to the optimizer
- sb3_contrib.ppo_mask.MultiInputPolicy¶
alias of
MaskableMultiInputActorCriticPolicy
- class sb3_contrib.common.maskable.policies.MaskableMultiInputActorCriticPolicy(observation_space, action_space, lr_schedule, net_arch=None, activation_fn=<class 'torch.nn.modules.activation.Tanh'>, ortho_init=True, features_extractor_class=<class 'stable_baselines3.common.torch_layers.CombinedExtractor'>, features_extractor_kwargs=None, normalize_images=True, optimizer_class=<class 'torch.optim.adam.Adam'>, optimizer_kwargs=None)[source]
MultiInputActorClass policy class for actor-critic algorithms (has both policy and value prediction). Used by A2C, PPO and the likes.
- Parameters:
observation_space (
Dict) – Observation space (Tuple)action_space (
Space) – Action spacelr_schedule (
Callable[[float],float]) – Learning rate schedule (could be constant)net_arch (
Optional[List[Union[int,Dict[str,List[int]]]]]) – The specification of the policy and value networks.activation_fn (
Type[Module]) – Activation functionortho_init (
bool) – Whether to use or not orthogonal initializationfeatures_extractor_class (
Type[BaseFeaturesExtractor]) – Uses the CombinedExtractorfeatures_extractor_kwargs (
Optional[Dict[str,Any]]) – Keyword arguments to pass to the feature extractor.normalize_images (
bool) – Whether to normalize images or not, dividing by 255.0 (True by default)optimizer_class (
Type[Optimizer]) – The optimizer to use,th.optim.Adamby defaultoptimizer_kwargs (
Optional[Dict[str,Any]]) – Additional keyword arguments, excluding the learning rate, to pass to the optimizer